Generalization of Diffusion Models Arises with a Balanced Representation Space (ICLR ‘26)
1University of Michigan · 2Georgia Institute of Technology · *Equal contribution
TL;DR. Diffusion models' generalization (ability to generate novel samples) should be studied together with their representation learning (ability to perceive and understand samples).
Generalization is a strong bias/capability of neural networks
A generalizing model learns beyond the finite training set to approximate the underlying distribution \(p_{\mathrm{gt}}\) (often human-defined or perceived).

Generalization of diffusion models. Learning \(p_{\mathrm{gt}}\) allows the model to generate novel and realistic samples.
For diffusion models, this means generating realistic (in-distribution) images not present in the training set, and this is done by from training samples \(\bm{x}_{i=1\dots n}\sim p_{\mathrm{gt}}\).
The denoising network is trained to recover clean samples from noisy inputs across noise levels:
$$ \frac{1}{T}\sum_{t=0}^{T} \mathbb{E}_{\bm{x}\sim p_{\mathrm{gt}},\,\bm{\epsilon}\sim\mathcal{N}(\bm{0},\bm{I})} \!\left[\big\|\bm{f}_{\bm{\theta}}(\bm{x}+\sigma_t \bm{\epsilon},t)-\bm{x}\big\|^2\right]. $$After training, we learn a rich that removes noise with respect to \(p_{\mathrm{gt}}\). Sampling then starts from noise and iteratively denoises into meaningful images, i.e., generalizes.
However, such success is not guaranteed by neural networks' ability to approximate any function. Otherwise, they would overfit to an empirical solution that denoises inputs toward training samples and effectively memorizes them. So what bias of networks allows diffusion models to generalize? We connect it to another crucial aspect: their learned internal representations.
Looking into networks.
We study training of parameterized diffusion models as a two-layer ReLU network, under a single noise level. Since it is also a , we call it ReLU-DAE. This is a minimal nonlinear model for studying representation learning and denoising.
Lineage: Pascal Vincent, "A Connection Between Score Matching and Denoising Autoencoders," Neural Computation, 2011; and Yoshua Bengio, Li Yao, Guillaume Alain, and Pascal Vincent, "Generalized Denoising Auto-Encoders as Generative Models," NeurIPS 2013.
We prove that under the diffusion loss:
(i) memorization corresponds to \(\bm{W}_1, \bm{W}_2\) storing raw samples in the weights, approximating \(\bm{f}_{\mathrm{emp}}\);
(ii) generalization corresponds to \(\bm{W}_1, \bm{W}_2\) learning local data statistics, efficiently approximating \(\bm{f}_{\mathrm{gt}}\);
(iii) a hybrid regime due to data imbalance.
Three regimes in ReLU-DAE learning. Memorization (left), hybrid (center), and generalization (right).
Representation learning in real models:
Memorized samples align perfectly with stored structures and produce spiky representations: a strong single-neuron stimulation or retrieval of a specific training example.
Generalized samples align with a broader set of structures, yielding balanced representations that compose across neurons and reflect the underlying distribution, as coordinates for the image manifold.
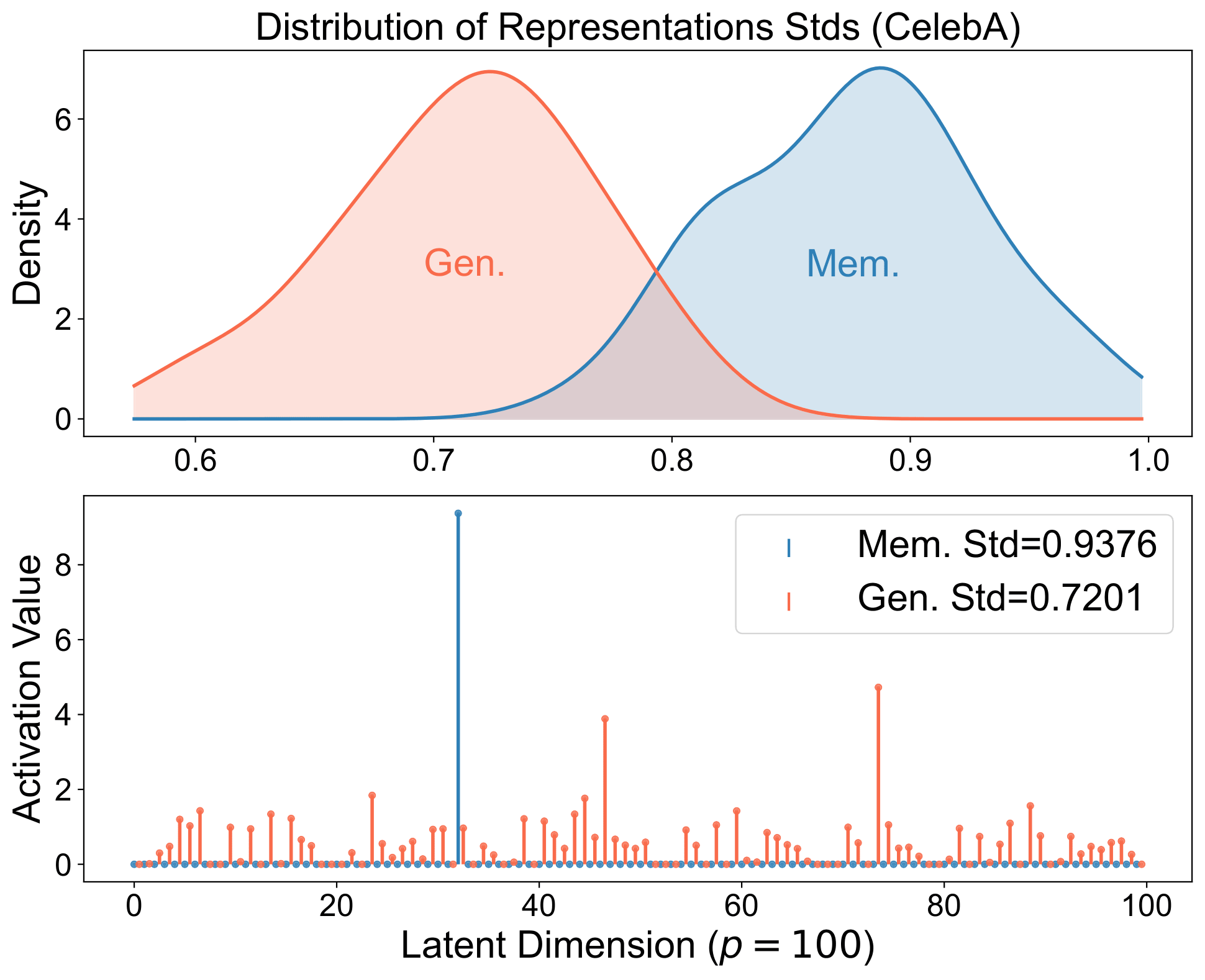
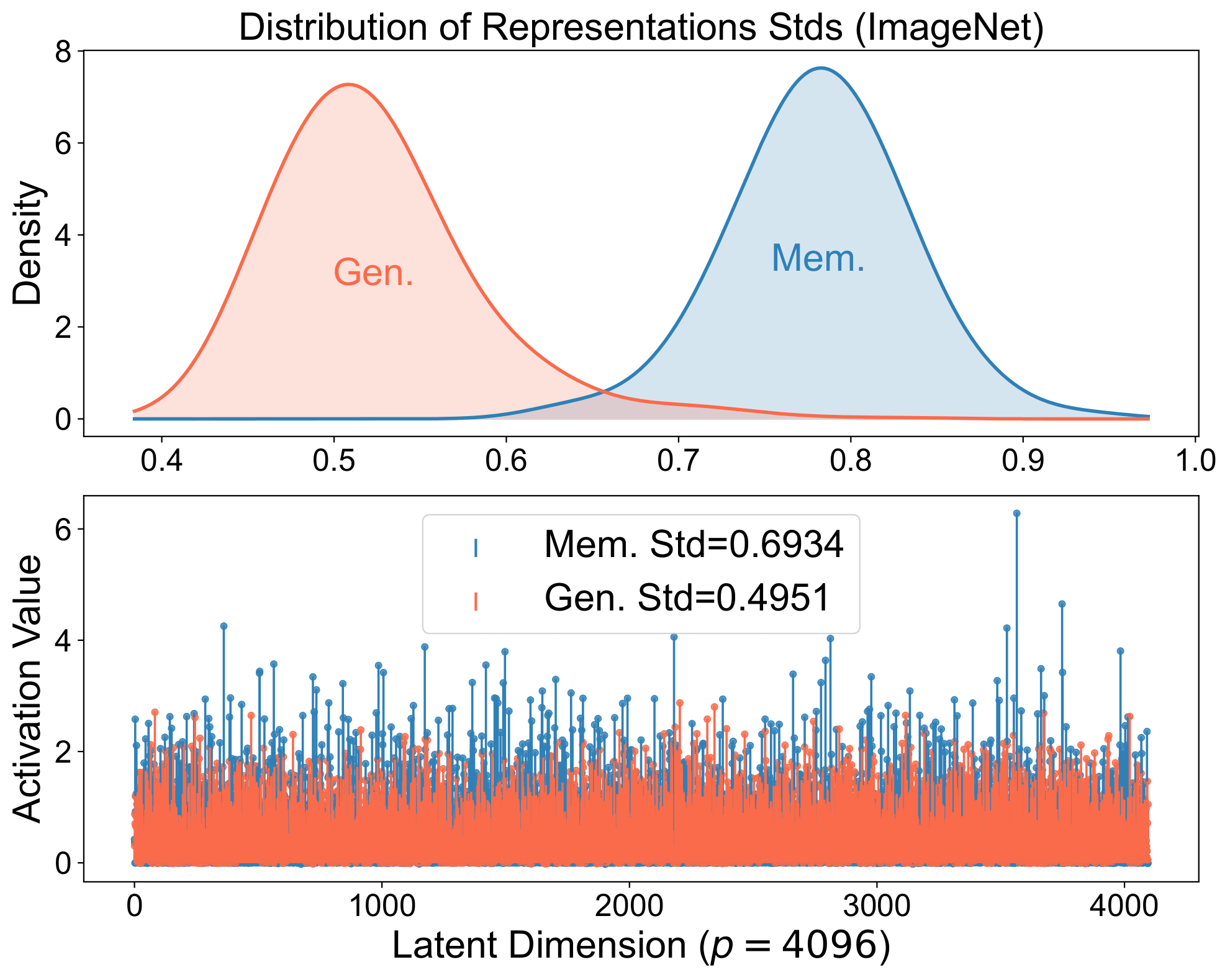
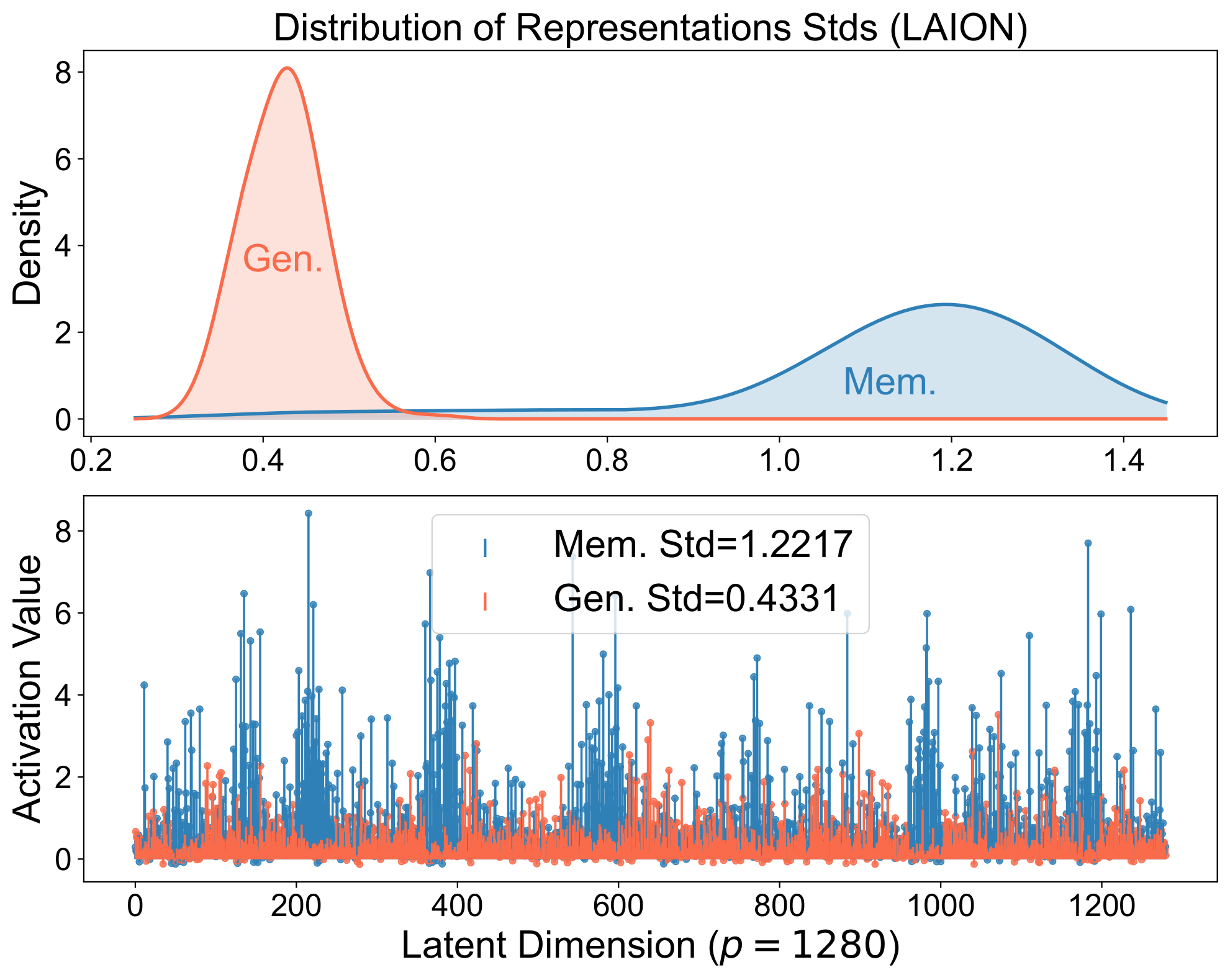
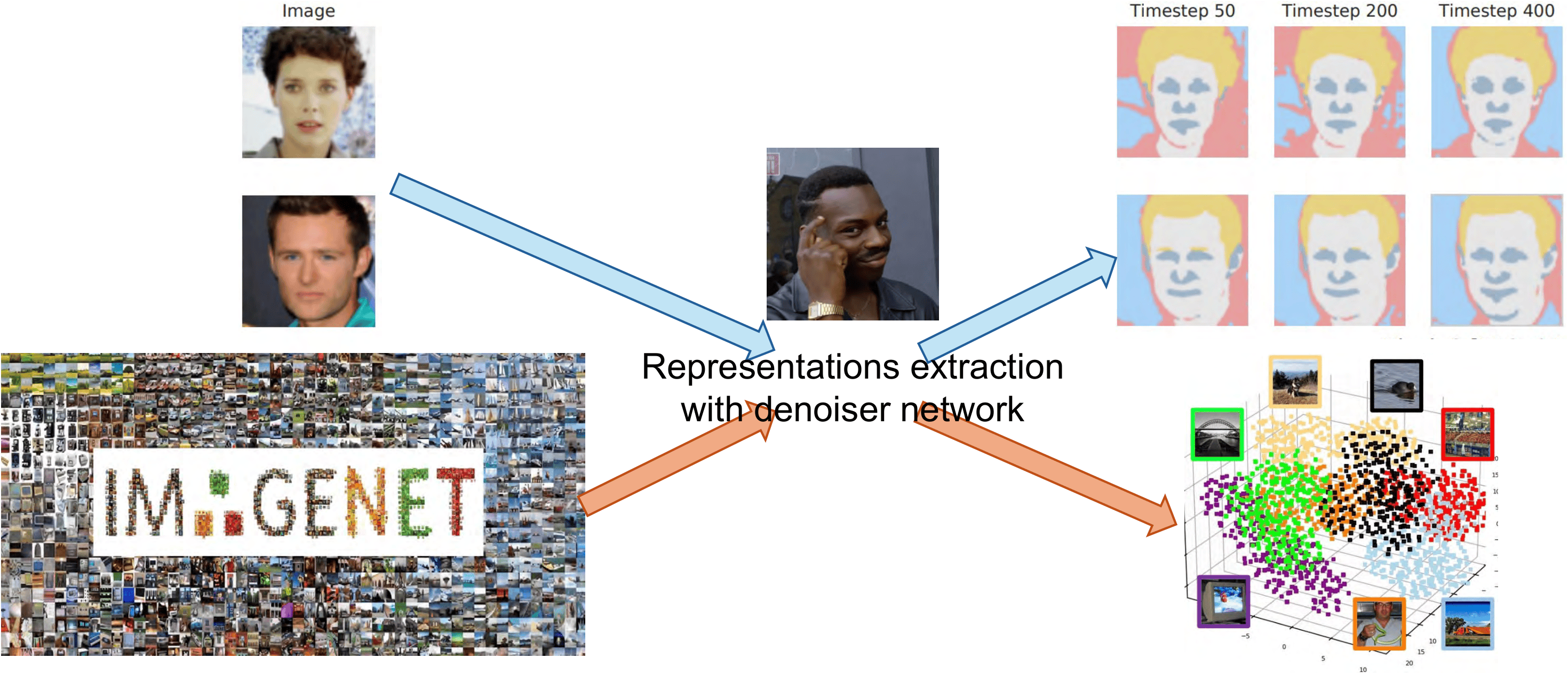
Same signature in real diffusion models. The spiky-vs-balanced separation persists in large models.
Generalized reps can also be to change the final output, whereas memorized ones cannot.
Lvmin Zhang, Anyi Rao, and Maneesh Agrawala, "Adding Conditional Control to Text-to-Image Diffusion Models," ICCV 2023.
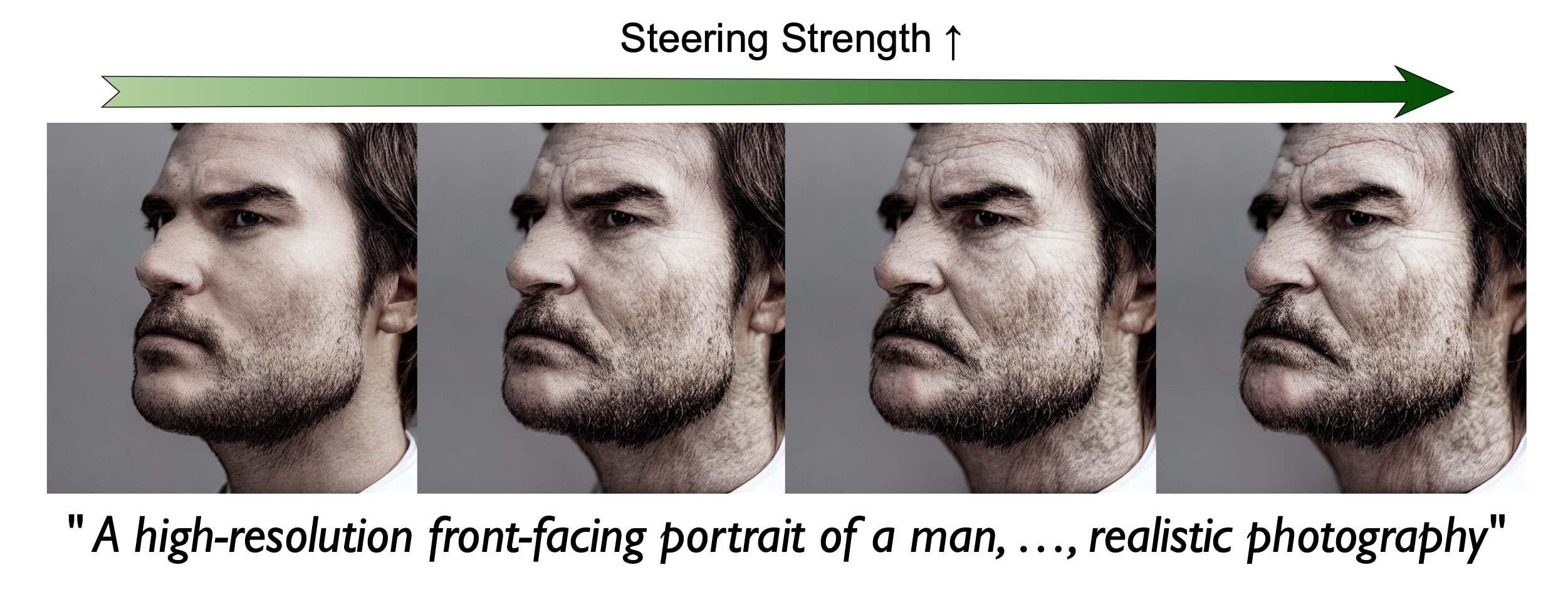
+Old (Gen.)

+Old (Mem.)
Image editing via representation steering. Works for generalized samples, not for memorized samples.
Our theory starts from a simple two-layer network, but
we believe it reflects a fundamental mechanism in deep models: they project noisy inputs onto learned low-dimensional structure, arranging visually similar inputs into similar and meaningful activations (via ReLU gating in our theory).
This smart arrangement underlies their behavior and shares an intuitive similarity with human perception. Internally, this appears as representation learning.
Compressing: Sam Buchanan, Druv Pai, Peng Wang, and Yi Ma, Principles and Practice of Deep Representation Learning, online book, 2026. Denoising: Dmitry Ulyanov, Andrea Vedaldi, and Victor Lempitsky, "Deep Image Prior," CVPR 2018.